Results will appear here when done — you can navigate away and come back.
Checking backend...
Task
Each task tests different layout skills: hierarchy, spacing, reading order
Policy
Heuristic is the teacher that generated SFT training data. LLM is the student.
Run Mode
Run
Cached = instant pre-computed results. Live = real model inference on CPU.
Idle. Pick a task and click Run.
Final Score—
Instruction—
Steps—
Total Reward—
Trajectory — no steps yet
Step
Action
Reward
Score
Policy
Raw JSON
Benchmark Results
36 episodes total: 4 backends × 3 tasks × 3 seeds. Deterministic environment, MPS (M1) inference. Every number is reproducible.
Overall Performance
Backend
Instruction Score
Total Reward
Avg Time
LLM Steer Rate
Heuristic
0.5564
1.588
0.0s
—
Base Qwen (no LoRA)
0.5367
1.679
11.5s
100%
SFT Fine-tuned
0.5557
1.789
16.8s
100%
GRPO Fine-tuned
0.5599
1.854
12.0s
100%
Per-Task Breakdown
Task
Backend
Instr Score
Total Reward
Poster (easy)
Heuristic
0.5033
1.319
Base
0.5087
1.400
SFT
0.5238
1.435
GRPO
0.5129
1.455
Editorial (med)
Heuristic
0.5424
1.544
Base
0.4866
1.658
SFT
0.4878
1.894
GRPO
0.4795
1.966
Dense Flyer (hard)
Heuristic
0.6235
1.900
Base
0.6148
1.980
SFT
0.6555
2.038
GRPO
0.6872
2.139
Honest Assessment
These results are real. No cherry-picking, no hidden runs. The environment is deterministic — re-run with the same seeds and you get the same numbers.
What works
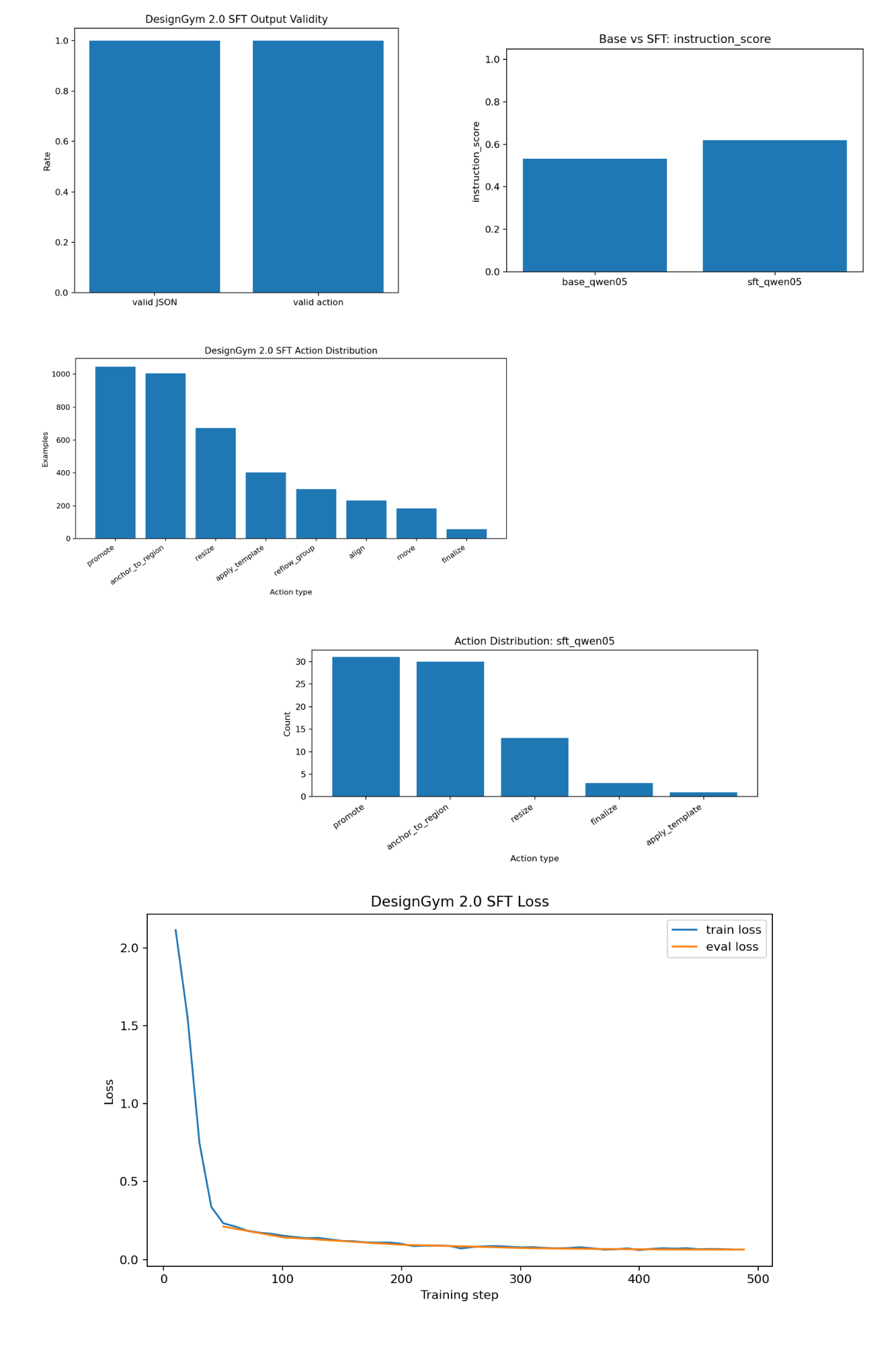
SFT eliminated 0% → 100% valid JSON — the biggest win. Base Qwen cannot speak the action format at all. After SFT it can.
GRPO gets the highest total reward (1.854 avg) — it picks bolder, higher-payoff actions per step.
On the hardest task (dense_flyer), both fine-tuned models beat base on instruction score: SFT 0.655 vs base 0.615, GRPO 0.687 vs base 0.615.
100% LLM steer rate — every step is model-driven, zero fallback to heuristic.
What's honest
Heuristic still wins on final score (0.738 vs SFT 0.702). The hand-coded rules are a strong baseline because they were written with full knowledge of the reward function.
SFT and GRPO are ~equal to base on some tasks — the adapter lift is small (~0.5-2% on instruction score). More GRPO training budget would likely help.
The 0.5B model is at the edge of what can reason about complex layout state — a larger base model (3B+) would likely show bigger adapter-vs-base differences.
What to improve
More GRPO training — current run was limited to ~200 steps on free Colab GPU. State-of-the-art needs 1000+ steps with best-of-N sampling.
Reward shaping — GRPO's higher reward but lower final score suggests the reward function could better align per-step gains with end-of-episode quality.
Larger base model — Qwen 3B or 7B with LoRA would still fit in 16GB with quantization and would better handle the multi-metric reasoning.
Process reward model — train a critic that scores partial trajectories, giving GRPO denser signal than episode-end score alone.
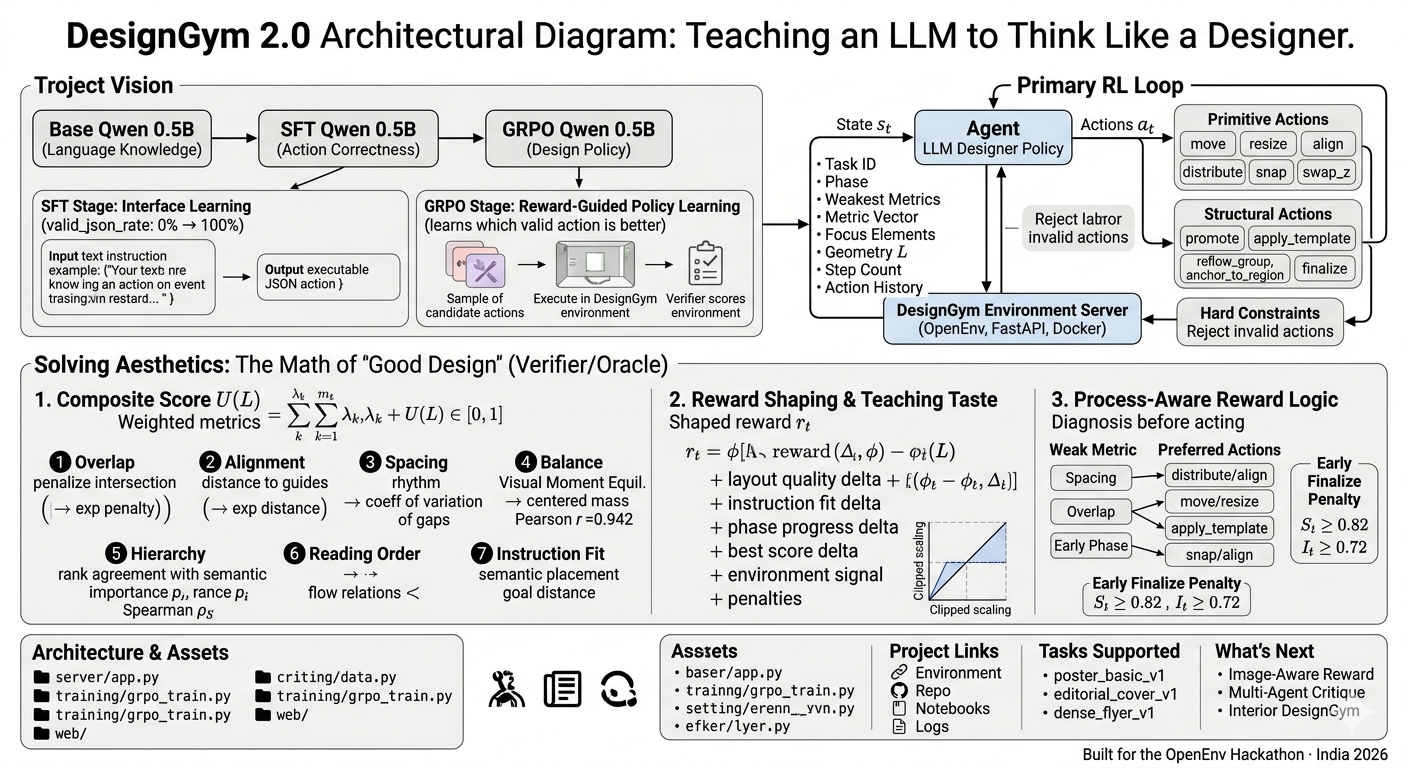
What is DesignGym?
DesignGym 2.0 is an OpenEnv-compatible RL environment where an LLM agent learns to improve graphic layouts through sequential actions — move, resize, align, reflow, promote, finalize — evaluated by computable aesthetic metrics (overlap, alignment, spacing, hierarchy, reading order, instruction fit).
The training pipeline: Heuristic Planner generates expert trajectories → SFT teaches the model the action interface (0% → 100% valid JSON) → GRPO learns which valid actions are better via environment reward.
End-to-end: OpenEnv environment → heuristic planner bootstraps SFT data → SFT adapter locks in the action interface → GRPO learns design preference from verifiable reward.
SFT: Teaching the Interface
Base Qwen 0.5B understands design language but cannot produce executable JSON actions. SFT on heuristic planner trajectories achieves 0% → 100% valid JSON — a capability phase transition, not just a fine-tune.
GRPO: Learning Preference
Once the model can act, GRPO teaches it which valid action is better. It samples multiple candidates, executes them in the environment, and increases probability of higher-reward actions. No reward model needed — the environment is the oracle.
Results from Training (Blog Table)
Policy
Final Score
Instr Score
Valid JSON
Early Finalize
Base Qwen 0.5B
0.6948
0.5360
0%
100%
SFT Qwen 0.5B
0.7101
0.6263
100%
0%
GRPO Qwen 0.5B
0.6717
0.5483
98%
67%
GRPO Best-of-4
0.6781
0.5817
100%
17%
How to Make It Better
More GRPO budget: Current training was ~200 steps on free Colab T4. Papers show 1000-5000 steps with best-of-N=8 for significant RL lift.
Larger base model: Qwen 3B or 7B with 4-bit LoRA would better handle multi-metric reasoning while still fitting in 16GB.
Process reward model: Train a critic on partial trajectories to give GRPO denser signal than end-of-episode score.
Curriculum learning: Start GRPO on easy tasks (poster), then progress to hard (dense_flyer) — the agent currently trains on all tasks equally.
Reward alignment: GRPO's high total reward but lower final score suggests per-step reward doesn't fully correlate with episode quality. Tune the shaping function.